Blog Agent
상한가 종목 분석 블로그 글을 도메인 데이터 파이프라인으로 자동 생성.
7단 RAG + 5중 검증 + Gemini 자동 검증으로 수치 환각 0건 달성 (v13)
상한가 분석 글을
매일 쓰는 게 왜 힘든가
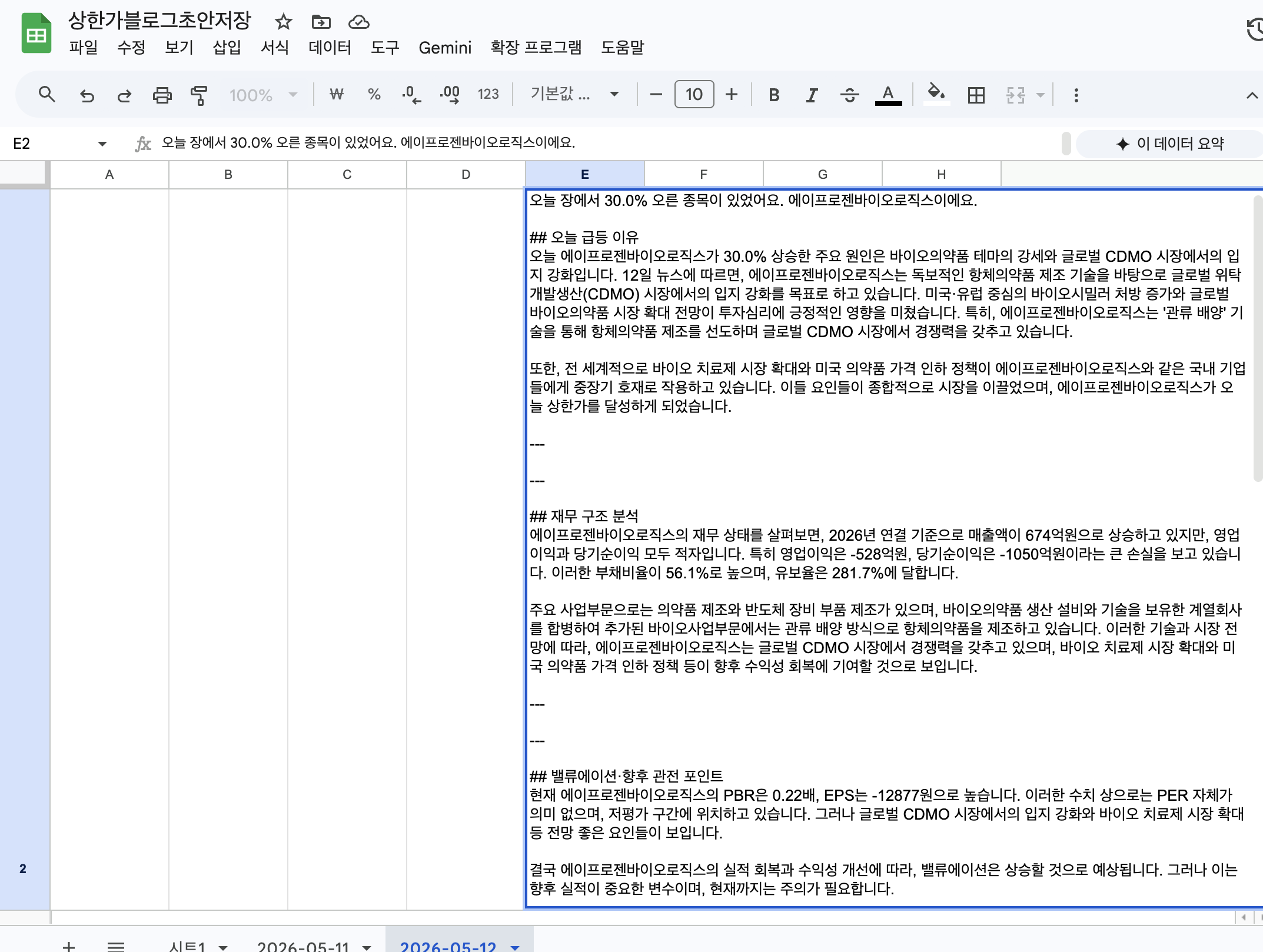
수급·재무·공시 데이터를 일일이 확인하지 않으면 LLM 할루시네이션이 틀린 수치를 생성한다
상한가 종목마다 DART 공시 확인 + 뉴스 검색 + 재무 분석을 매번 수동으로 하면 한 글에 2시간 이상 소요
작성자 컨디션에 따라 글의 구조와 깊이가 달라진다. 독자 신뢰를 위한 형식 표준화가 필요
상한가 감지 → 이슈 점수 → RAG + LLM → 다중 배포
감지
상한가 종목 탐지
수집
6개 소스 병합
점수
필터링
유사글 2개 주입
생성
/ Gemini (클라우드)
검증
품질·Gemini
Obsidian · RAG 인덱싱
5중 검증 시스템으로 팩트 오류 최소화
순차적으로 통과하지 못하면 재처리. Gemini 검증 critical → 자동 배포 차단. 최종 통과 글만 다중 배포 → 수치 환각 0건 달성 (v13 기준)
13번의 이터레이션
4개 채널 자동 다중 배포
Google Sheets · Instagram · Obsidian · RAG 인덱싱
5중 검증을 통과한 글이 동시에 4곳으로 배포됨. Sheets에는 검증 점수·종목명·버전이 기록되어 검수자가 빠르게 리뷰 가능.
자동화 범위
상한가 감지 → 데이터 수집 → 이슈 점수 → RAG + LLM 생성 → 5중 검증 → Google Sheets · Instagram 카드뉴스 · Obsidian · RAG 인덱싱 전 과정 무인 실행
v13 기준: 7단 RAG + 5중 검증 + Gemini 자동 검증으로 수치 환각 0건 · 상한가 종목 자동 선정 → 4개 채널 동시 배포
완전 자동화보다 신뢰할 수 있는 반자동화
다음 단계
Obsidian RAG DB 지속 축적으로 섹터별 Few-shot 품질 자동 개선. Gemini 검증 쿼터 소진 시 4단계 폴백 모델 큐 운영 중. 다종목 병렬 분석 + 신뢰성과 속도의 트레이드오프를 사용자가 조절할 수 있는 구조가 목표